Multi-Cloud Reliability: Ensuring Performance Across Distributed Environments

Introduction
For businesses operating across a mix of AWS, Azure, GCP, SaaS, and on-premises infrastructure, simple “up” or “fast” is no longer an adequate measure; these are constantly shifting goals. Multi-cloud reliability has escalated from a specialized SRE metric to a fundamental business imperative.
The costs of failure underscore this shift. According to ITIC’s 2024 research, over 90% of mid-size and large enterprises face costs exceeding $300,000 for just a single hour of downtime, with many reaching millions. Other studies, such as those cited by Forbes, indicate that minute-long outages can cost large organizations up to $9,000 per minute. Therefore, achieving multi-cloud reliability is about more than just ensuring servers are running. It requires delivering consistent performance and system availability across all disparate environments, all while effectively managing tool sprawl, alert overload, and siloed data.
This is exactly where Scout-itAI , a cloud-native event intelligence service, can step in to help because that’s what it’s designed for.
Why Multi-Cloud Reliability Matters More Than Ever
Essentially, most enterprises now are hybrid and multi-cloud by default they use a mix of cloud providers, legacy systems and SaaS. That complicates things and brings real risks:
- A simple issue with a DNS in one region can affect a checkout process in another.
- A noisy alarm about a network issue could be hiding the signal that an API gateway is about to fail.
- A tiny 2% increase in latency on a key path can quietly knock your conversion rates.
Analysts are now saying that AI-driven observability platforms are a must for enterprise resilience and that organizations need to move beyond just raw dashboards to actionable insights and automation.
So, in this context, multi-cloud reliability, performance, and resilience become critical capabilities:
- Multi-cloud performance: Can you keep response times consistent across providers & regions?
- Multi-cloud resilience: Can you absorb failures without any impact on the users?
- Multi-cloud availability: Can business-critical services meet their SLAs even if individual components fail?
Turning Multi-Cloud Monitoring Data into Business-Ready Reliability Insights
The Hidden Enemies of Multi-Cloud Reliability
If you’re an IT Ops, NetOps, or data leader, these will sound familiar:
| Problem | Impact on Reliability | What You Actually Need |
| Disconnected monitoring tools | No single version of truth across clouds and domains | Unified multi-cloud observability |
| Alert fatigue & “pager spam” | Teams ignore or mute alerts, missing true incidents | Noise reduction & event correlation |
| Overload of siloed metrics | Thousands of metrics, no clear reliability narrative | Business-level reliability scores & KPIs |
| Inability to correlate across domains | Network vs app vs cloud vs third-party finger-pointing | End-to-end path-level visibility |
| Manual troubleshooting | Long MTTR, higher downtime costs, frustrated teams | AI-assisted root cause & automated actions |
Considering the complexities introduced by hybrid and multi-cloud environments, ensuring reliability and reasoning about all potential failure modes is virtually impossible for human teams. This inherent difficulty is driving the industry away from a simple focus on “more data” and toward advanced solutions like event intelligence and agentic AI.
What “Good” Multi-Cloud Reliability Looks Like
Before you update, it helps to define where you want to be. A mature multi-cloud reliability posture often includes:
- A single reliability metric per service that can be understood by both engineers & executives, something like Scout-itAI’s Reliability Path Index (RPI).
- End-to-end, path-aware visibility that looks at service-delivery paths from user to app to network to cloud provider not just “CPU is fine” or “APM looks green”.
- Standardized, cross-domain scoring that measures reliability consistently from mainframe to SD-WAN to cloud apps.
- Predictive insight, not just retrospective dashboards that can answer “if we change X, what happens to reliability and business impact?”.Provide proactive infrastructure monitoring with AI (anomaly detection + prediction)
- Multi-cloud availability and failover strategies that are backed by playbooks and automations to keep services resilient when a provider, region or key dependency misbehaves.
This isn’t just about buying another monitoring tool, it’s about treating reliability as a tangible, measurable business asset.
From Monitoring to Intelligence: How Agentic AI Changes the Game
Traditional monitoring tools are good at collecting metrics, but they’re not great at telling a story about reliability across distributed systems.
Scout-It AI’s Event Intelligence Service was built to bridge the gap between what business wants and what tech can deliver by harnessing agentic AI, generative insights and forecasting:
1. Reliability Path Index (RPI): One Score to Align Tech and Business
Instead of drowning in dashboards, Scout-itAI gives each critical service an RPI score a patented 13-bucket model based on 15+ years of enterprise reliability data.
- Aggregates telemetry from many tools into one reliability score per service
- Makes multi-cloud reliability understandable to both NOC engineers and the C-suite
- Helping you to compare reliability across different domains: mainframe, cloud apps, SD-WAN, SaaS
It all comes down to solving one big pain point: “How on earth do I get standardized scores of reliability across different domains?”
2. Predictor: Monte Carlo Forecasting for Multi-Cloud Change Risk
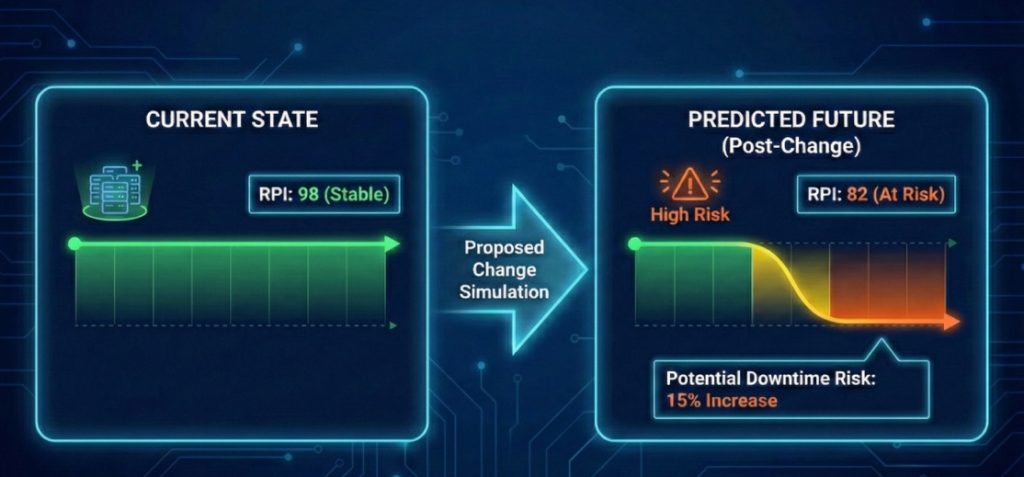
Navigating multi-cloud changes can be challenging. However, with Scout-It AI’s Predictor, you can forecast the impact of proposed changes on your Reliability Performance Indicator (RPI) score and reliability ROI by running up to 100,000 Monte Carlo simulations.
That means you can:
- Model “what-if” scenarios before you touch production
- Prioritize changes with the best reliability return on investment
- Tie reliability decisions directly to business risk and availability
That’s how you transition from firefighting to predictive, data-driven multi-cloud resilience.
3. Blender & Trender: Finding Patterns in the Noise
In multi-cloud environments, the signal gets lost in the noise.
- Blender (Six Sigma analysis) uses real-time statistical techniques to find patterns in alarms and metrics, surfacing what’s really impacting multi-cloud performance and availability.
- Trender (Kaufman’s Adaptive Moving Average / KAMA) keeps an eye on long-term performance against a 100-day baseline, catching subtle degradation before it turns into an incident.
Together, they turn siloed metrics into clear narratives about how hybrid and multi-cloud reliability are trending.
4. Agentic Workforce & Automation: Faster MTTR, Less Human Toil
Scout-itAI’s agentic workforce framework uses orchestrator and sub-agents to:
- Correlate events across clouds, networks, and apps
- Escalate only worthy, business-relevant issues
- Trigger safe automations and self-correction where it makes sense
Promise Theory-based governance ensures these agents behave in a predictable and transparent way reducing hallucination risk, while still speeding up troubleshooting.
The result: lower MTTR, reduced alert fatigue, and more time for your teams to build, not just fix.
5. Universal Hybrid Cloud Monitoring & Integrations
Reliability depends on visibility. Scout-itAI:
- Monitors AWS, Azure, GCP, and on-prem with up to 12 months of performance history
- Integrates with tools like Dynatrace, Splunk, Broadcom DX NetOps/OI, AppNeta, and more, so you don’t have to rip and replace your observability stack
- Normalizes telemetry into the RPI model, giving you a unified, reliability-centric view across your multi-cloud observability landscape
Getting Started for IT and Business Leaders
You don’t need to rip everything out to get a handle on multi-cloud reliability. Here’s a practical roadmap:
- Identify your critical services and paths
Map the top 5–10 business journeys (e.g., checkout, quote, login) across clouds, networks, and dependencies. - Establish a reliability scorecard
Use a model like RPI to condense telemetry into a single score per service, and track it alongside business KPIs (revenue, conversions, NPS). - Consolidate signal, not tools
You can keep existing tools, but consolidate their output into a unified event intelligence layer that reduces noise and highlights correlated issues. - Introduce forecasting into change management
Before major releases or cloud migrations, run simulations to understand how changes will impact multi-cloud availability and performance. - Automate the obvious
Start with low-risk, high-frequency issues (e.g., predictable saturation, misconfigurations) and let agentic AI assist with remediation—under human governance. - Report in business language
Use reliability scores and plain-language insights to show your CEO and stakeholders how you are making the business more reliable, without “techy jabber.”
Protect Your Multi-Cloud Reliability with Scout-itAI
Multi-cloud is a permanent fixture in the modern IT landscape. The competitive advantage, however, lies in an organization’s ability to transform its distributed, complex infrastructure into a source of reliable, predictable customer experiences.Scout-itAI helps you:
- Standardize reliability across any environment or vendor
- Predict the impact of changes before they cause downtime
- Reduce noise and MTTR with agentic AI and event intelligence
- Communicate reliability in terms the business immediately understands
If you’re ready to break free from all those separate metrics and confusing dashboards, it’s time to switch to a reliability-first approach.
Book a Scout-itAI Demo and see how RPI, Predictor, and agentic AI can help you ensure multi-cloud reliability across your distributed environments.
Conclusion
Multi-cloud reliability now extends beyond simple “uptime.” It is about maintaining consistent performance and resilience across distributed environments, including AWS, Azure, GCP, SaaS platforms, and on-premise infrastructure, even in the face of continuous change and an overload of alerts. Scout-itAI enhances reliability by consolidating fragmented telemetry into a clear, unified view using its Reliability Performance Index (RPI). It proactively manages change risk with the Predictor feature and significantly reduces alert overload through intelligent event management and automated, agentic workflows.
Ready to achieve measurable, explainable, and improvable reliability across your cloud environments? Schedule a Scout-itAI demo.
Frequently Asked Questions
Multi-cloud reliability is the ability of your services to remain available, performant, and resilient across multiple cloud providers, regions, and on-prem environments even when individual components fail.
You measure it using end-to-end service metrics (latency, errors, availability, SLOs) and composite scores like Scout-itAI’s Reliability Path Index (RPI), which condenses many telemetry sources into a single reliability score per service.
Single-cloud reliability focuses on one provider’s stack. Multi-cloud reliability must account for inter-cloud traffic, network paths, SaaS dependencies, and failover strategies, making correlation and event intelligence far more important.
AI can correlate events across domains, forecast failure scenarios, reduce alert noise, and recommend or trigger remediation steps cutting MTTR and improving multi-cloud performance and resilience.
Event intelligence is the layer that sits above raw logs and metrics, correlating events, scoring reliability, and surfacing root causes. Scout-itAI is an event intelligence service that turns telemetry into plain-language answers and actions.
Scout-itAI uses Blender (Six Sigma analysis) and its agentic workforce to cluster related events, filter noise, and escalate only what matters to business-critical services mapped directly to RPI scores and user impact.
Yes. Scout-itAI integrates with platforms like Splunk, Dynatrace, Broadcom DX NetOps/OI, and others, ingesting their telemetry and translating it into a unified reliability model instead of replacing them.
Forecasting with Monte Carlo simulations lets you test “what-if” scenarios such as shifting traffic between regions or changing instance types so you can see likely effects on reliability before committing changes.
No. While it serves SREs, NetOps, and IT leaders, its plain-language insights and RPI score are built so CIOs, CDOs, and business stakeholders can understand reliability risks and improvements without deep technical detail.
Start by identifying your top critical services, then connect Scout-itAI to your existing observability tools. From there, you can begin scoring reliability with RPI, enabling forecasting, and layering in agentic AI automations guided through a Scout-itAI demo.

Tony Davis
Director of Agentic Solutions & Compliance